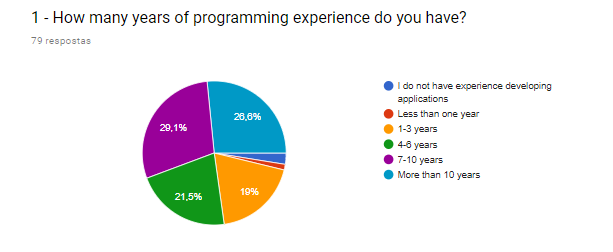
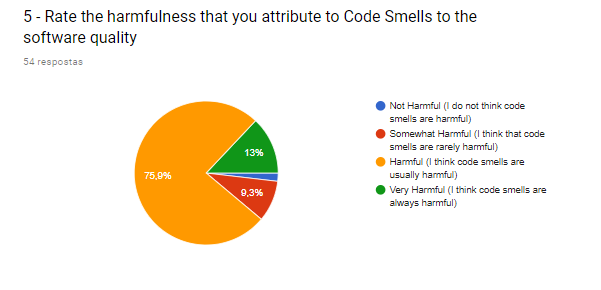
| Code smells often indicate or lead to bigger problems. Those bigger problems can make a code base fragile, difficult to maintain, and prone to errors. |
| It makes it difficult to read and maintain your code base. |
| It difficults the readability of the code, that can lead to the introductions of bugs. |
| They tend to indicare over complication or lacking SOLID principals. |
| Code smells have impacts on code maintainability, especially when the code is not clear what should be done. This makes the misinterpretation of what the code should do, and if there is no automated testing to guide the developer on what the code should do, we often have the rework to rewrite all the functionality, because it is simpler to develop from scratch. that improve a code snippet. |
| It can impact very badly in the long run of software development, causing degration of code quality. |
| Code smell is a way to detect bad decisions that can impact directly the runtime and the business around the software. |
| This can hardly be evaluated out of context. Some harmfulness is caused by the broken window effect anyway. |
| Smells are indications something MIGHT be wrong and it's LIKELY that you are violating some aspect of good OO design. But then again maybe not. |
| It usually impacts on maintainability the presence of code smells, when the time of modify the existing code arrives, code smells make that changes easy to break the code. I don't mark this as very harmful because it is preferable a well tested code with some code smells that a non tested software without code smells. |
| Code smell is an item for have a technical debt. Miss unit test is another item being harmful. |
| It will have direct consequences in quality, maintenance if the smell is not fixed. |
| In a common basis we work with scalable and mantainable software, so any code smell probably means, in future, a huge refactor. There are worse code smells like the blob and stuffs, but any of them I consider a problem. |
| They always represent a relevant risk to the maintenance and, most of them, to future implementations, demanding a lot of time with refactor work. |
| If this problem isn't dealt with it'll spread, the cost and effort to fix it'll increase. |
| At the first moment, this wouldn't a big problem, but in the future, it will cause problems to maintain the application. |
| It usually means you are working with people who don't care about the quality of the work or is in a unconscious incompetence level, which means that they think they know what they are doing but they are clueless. |
| They increase the complexity of the codebase, and the cognitive load on engineers. This leads to decreased productivity and increased bugs. |
| Code smells make software readability and comprehensibility worse. That itself already degrade software quality. Moreover, code smells can make it harder to find bugs in the software, since you can only find bugs in code that you can read, and understand. |
| Code smells tend to make code understanding difficult and software maintenance very difficult. |
| Your code is going to be confusing to read. |
| Long methods require more time for maintenance and many times, require devs with more experience. |
| Code smells usually indicates that something is wrong. When you have, for example, long methods, code readability decreases and therefore system maintenance is adversely affected. |
| Complex and long methods are difficult to manage. I like to split complexity in smaller chunks. |
| I do believe that code smells are harmful, but not usually harmful. There are specific cases that make them harmful, for example, when specific types of smells (or from similar categories) co-occur together. For instance, if a class contains a God Class, Intensive Coupling (or Dispersed Coupling) and more than one Feature Envy, in this case, the smells are harmful since they indicate that the class has a bigger structural problem. On the other hand, there are cases that smells are not harmful, for example, when a class has Lazy Class. |
| I believe that if you have unit test around it, it'd be Harmful or even Somewhat Harmful. Usually code smell is easy to be refactored when you have unit test. |
| If I need to improve, I can introduce a bug. |
| A piece of bad code tend to degrade fast after a lot of time without proper refactoring/maintenance, leading to a costly code evolution in the future. |
| I don't think that there are a mandatory relation between code smells and the harmfulness. But, naturally, in some cases code smells could contains characteristics of harmful code. |
| Some code can be ugly, but it works. |
| Not all codes smell are so harmful. |
| It is difficult to introduce changes in the business logic. |
| The presence of code smell could increase code maintenance work. |
| Code smell instances eventually hinder some major development tasks, especially when it comes to maintaining and evolving systems. I've had a hard time to read and change some large classes, complex methods, and intrincate hierarchies as well. |
| FindBugs, PMD, SonarQube |
| Sonar, tslint |
| PMD and JDeodorant |
| Tools for detecting code smells are important because humans are subject to failure, some practices that are clearly seen as code smells can always be detected by tools. Another point is that when you work on a project on your own, reviewing your own code for code smells has a much smaller impact than someone else's review, and puts a tool to help you with code review helps in those cases. |
| At some time of de development I consider checking all the project in order to find possible code smells. The problem is still the lacking of good software tools to do so. |
| Sonarqube, findbugs |
| Reek |
| Sonar, Findbugs, jacoco |
| Sonar, pmd, owasp, findbugs, vpav |
| Rubocop, Reek |
| PMD, CheckStyle |
| Idea, SonarQube, Js/TsLint are the ones i feel more confortable |
| Sonarqube and Sonarlint |
| Sometimes the changed code in a pull request doesn't have a full picture like duplication and etc. |
| Analyze Inspect Code - Android Studio |
| Most of themwere used as part of a CI solution, like sonar, and works pointing out code smells during the development process and suggesting improvements to solve them. |
| Rubocop, Pronto and Merge Requests with my team |
| Static code analyzers |
| I have read research on automatic code smell detection, but I don't recall any tool names. |
| It is not always in the development of the program to give yourself a macro view of it, so it is likely that some code smell will not be identified. |
| PMD |
| I've used in my career some tools to help me with code smells, like Checkstyle and more recently, we use Sonar. |
| After long years of experience I directly avoid all possible smells. For what I don't see at the first time there will be a code refactory. |
| I use one that has been developed in the research group that I work with. The name is Organic 2.0 |
| For Java I've used PMD and since I use IntelliJ IDEA, it has embedded static code analysis in it |
| Linters in general |
| lints, code formatters, code analyzers. |
| In the past I have used some tools such as PMD and JDeodorant. In both cases, the tools were used in non-graphical ways, just for research purposes. |
| Sonarqube |
| Sonar and ESLint |
| I've published a literature review on these tools at EASE 2016 ("A review-based comparative study of bad smell detection tools"). Part of my work was using tools like PMD, inFusion, JDeodorant, and etc. I've also used some of these tools to detect smells for study purposes. But, to be honest, mostly I've written my own detection scripts to run them on spreadsheets with code metrics data... LOL |
| I refactor to improve reusability and reduce fragile or error-prone code. How the code got to that state is irrelevant. |
| Code smells should be found by static analysis tools or reviewer. |
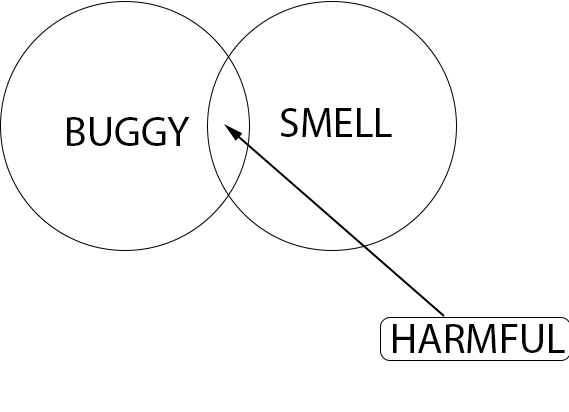
| Buggy code is something that already problematic to the software, so should be prioritized. |
| You may have code that has code smells, but if they have good automated testing, refactoring becomes a simpler and less risky task. And there are different code smells, some impact the readability of implementation details more, if the public interface of the code is well written, but the internal code is poorly made, refactoring becomes even simpler. The problem is more in code than badly done, do not work. We should prioritize covering them with tests, then adjust them as guided by the tests discovering current code problems, then refactoring them. |
| I always consider improving the code quality when fixing a bug. |
| We usually run sonarqube reports and try to fix all the warnings that are found. |
| Not all the problems are solved in a refactoring session, bug is your mission to deliver the best in that situation |
| Short term business value. Smells are best addressed by coaching and boy scout approaches. |
| Since a smell only indicates there might be a problem and harmful code definitely does have a problem, you should look at that first. |
| I would fix all of it but time is limited so priorities have to be set. |
| The question is really tricky because you will refactor always the worst part, otherwise the code will not work. I see what do you want to achieve with that question but the way you are asking that is really biased. |
| Code blocks that already have a bug and have code smell is much more problematic than a code smell. |
| Always leave the code better than before. |
| When touching on working code the risk to ruin something is greater than fixing already buggy code. |
| I usually look for problems that already exist or might become one in the future |
| Working on code smells means working on the prevention of most of bugs that could appear, so worry only about those who already have bugs attached too it is never enough. |
| All information is important. |
| because if you are refactoring you are trying to improve the code. Does not matter if it's horrible or somewhat acceptable. |
| Any improvements are worth the time. |
| I usually don't refactor buggy code when a bug is identified; I only fix it asap and leave possible refactoring for later. I apply a refactoring usually when the code is baddly structured. If a bug is found in the middle of the refactoring, I will be fixed also during the refactoring process, asap. |
| Codes that allow bugs are problematic because they are harmful to execution. |
| Refactoring process could insert new bugs, so I avoid to refactor code that it is working. |
| When refactor source vocês, we focus on long and complex codes, to facilitate future maintenance or upgrades. |
| When my team works with software maintenance, we usually get a problem and start reviewing it. Usually this problem represents a bug; therefore, we have the opportunity to improve some parts of the code. |
| In the real life we have to stay into the budget: so when, for whatever reason, I put my hand on a piece of code I try to fix/improve it. |
| I usually refactor my code when it is hard to understand/maintain, however, if I have to prioritize refactorings, I refactor elements that contain bugs and have smells. Since I'm already refactoring the code to get rid of the bug, I take the opportunity to remove the smell as well. The goal is to kill two birds with one stone. |
| I usually give priority to duplication, shotgun surgery, large class, naming, long methods, too many params. |
| In general, I tend to fix the bug (first) as fast as possible, which means I do not think about quality code at first. |
| Economics. Buggy code have hard effects on end user which tend to abandon your product after working for some time with a bug. |
| When refactoring, it is ideal to deal with all modules of the code, but due to some limitations, such as time, it is most important to look at fragile parts as harmful code. |
| Second criterion will be harmful. |
| There is no priority. |
| Well-written code avoids Code smells. |
| My academic background made me see refactorings as means to "clean the house" in terms of bad code structures rather than means to actually fix bugs. Eventually, refactorings can help fix a bug. Nevertheless, as a practitioner, I've tried the most to avoid refactoring buggy code elements. These elements should be changed only if necessary; otherwise, the damage can get worse (other bugs may emerge). |
| Code smells often indicate or lead to bigger problems. Those bigger problems can make a code base fragile, difficult to maintain, and prone to errors. |
| Yes. Security or maintenance issues. |
| Most of the code smells are dangerous in their own ways. They usually they make the codebase hard to maintain and modify. Or they introduce subtle bugs in certain scenarios. |
| Sometimes it can lead to early complex architecture. |
| Bad decisions of choosing patterns, the false senior developer (probably a old people in your team that you trust in a period, and when you see the disaster are made). In terms of code, inheritance, bad encapsulation, repeating yourself. |
| Misunderstandings waiting to happen. |
| Maintainability, readability. |
| As i said before, maintainability, you can code with code smells if it is a single person codebase because you know what have you done. But when there are more developers involved in a development, code smells make then doubt about the intentions or purposes of that code smell, is it there otherwise code doesn't work?, those kind of questions make developers lose time and commit errors. |
| Coupled code, fuzzy parameters names. |
| Maintenance. |
| God classes are the first example that comes to my mind. It doesn't have separation of concerns, do more than one job, if maintaining that code you will affect many points...there are many quality risks. It is even hard to focus the quality assurance in just one part of the application, forcing you to do a full regression. |
| Yes. It makes code harder to read and understand and this contributes to more bugs and more time debugging. |
| Code smells use to decrease code readability. |
| Yes. Sometimes, when you have a method or function too long, normally this is related to centrilize many tasks in only one place and that method/function is being responsible for activities that actually shouldn't be its responsibility. So, this decreases the software quality in terms of future maintenance or possible software evolution. |
| Efficiency, security and maintainability. |
| Fault proneness, software degradation, Error proneness, maintanance dificulty. |
| Sure, and they are many. As stated in Q.6, I've struggled to read and change smelly code many times before. Too messy code is irritating, right? Once I had to prepare a project for migration across programming languages. It was a hell of a work to read some pretty large classes with dozens of lenghy and complex methods. And what can I say about the uncountable dependencies among classes that made it hard to reorganize the code every now and then? |